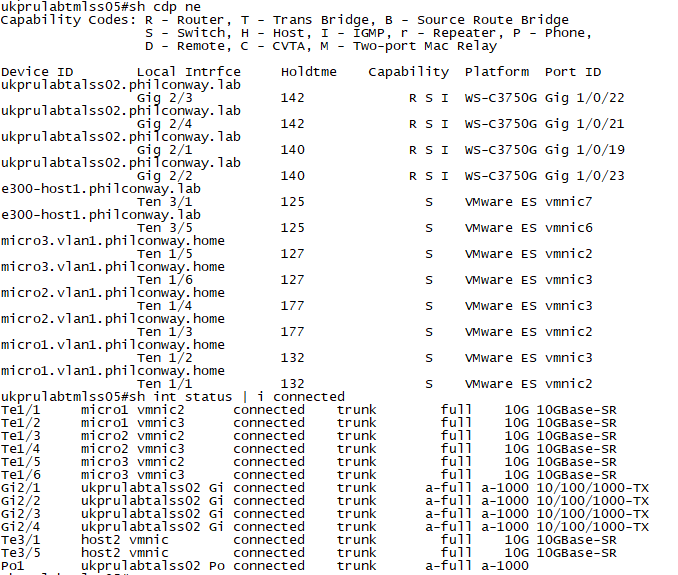
It’s been a few months now since vSphere 8.0 was released, so I decided to bite the bullet and try upgrading my hosts in my homelab. I thought I’d share my experience here for anyone running older (Sandy Bridge/Westmere Xeon) hardware in their homelabs who are thinking of doing the same.
vCenter Upgrade
Upgrading to vCenter 8 was fairly straightforward, only blockers to this was my install of NSX-V 6.14 (I used this to test NSX-V > NSX-T migrations) and a single host (HP Microserver N40L) stuck on vSphere 6.5, the last version of ESXi supported by this hardware. Both were flagged up by the VCSA installer at my first attempt.
With NSX-V removed and the single outstanding 6.5 host decommissioned, everything upgraded smoothly from a vCenter perspective.
Upgrading vSphere on HP Gen8 Hardware
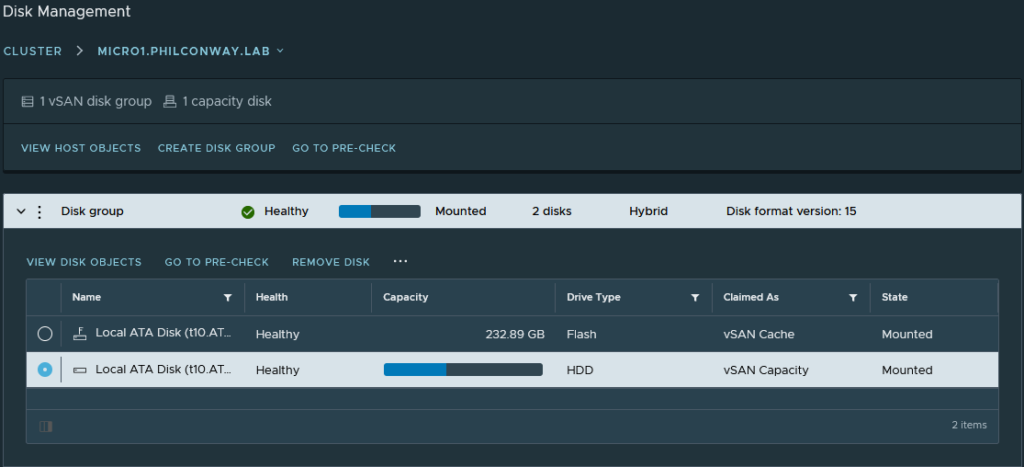
Next on the list was upgrading the hosts. I decided to start with my HP Gen8 Microservers (running Ivy Bridge Xeon E3-1265L v2s).
These CPUs are no longer supported, however the use of “allowLegacyCPU=true” as a boot option for the vsphere install (Shift+O on boot to set this) bypassed the check and allowed for an upgrade to take place.
Surprisingly, the upgrade process completed on all three Gen8 hosts successfully with no issues. A quick check of all hosts post-install showed all hardware being successfully detected and working correctly.
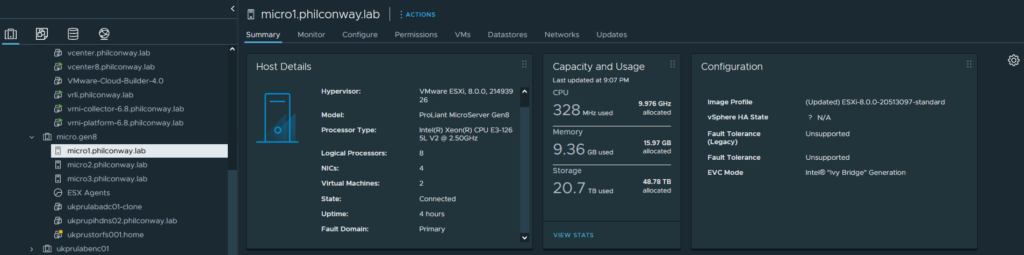
Upgrading my two HP DL380 Gen8s to vSphere 8 was a similar process – all hardware detected and working correctly.
Upgrading to vSphere 8 on DL380 G7
I have a pair of DL380 G7s running on Westmere CPUs (E5620s), with 128Gb RAM and 4TB of storage. I decided to try one to see how it fared with the new vSphere version.
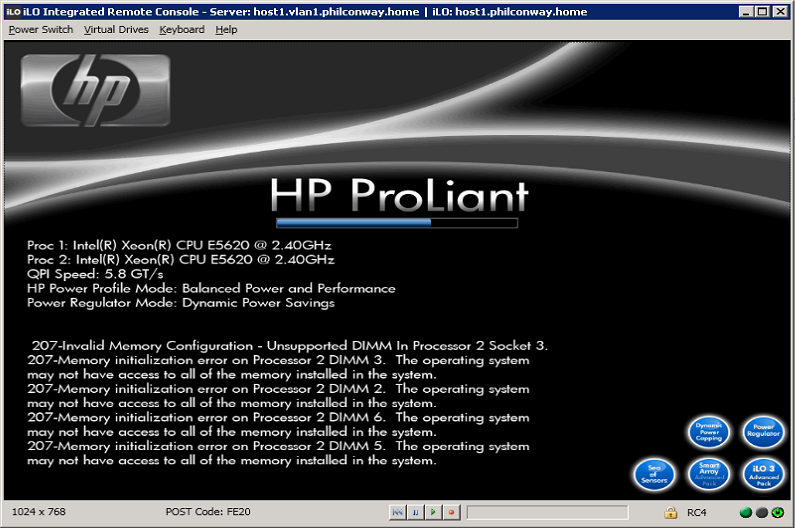
The first problem – due to not being powered on for a while, this particular box had trouble seeing it’s memory. Taking the cover off, removing the DIMMs, wiping the contacts and spraying some air cleaner into the sockets seemed to fix this 😉
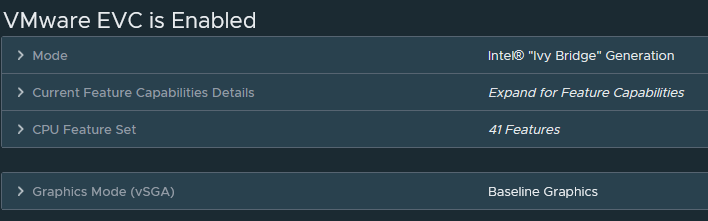
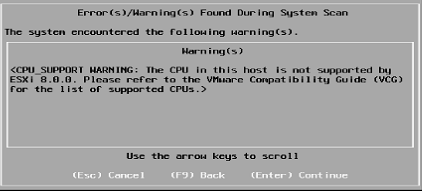
The install process seemed smooth enough – no warnings about unsupported hardware apart from the CPU:
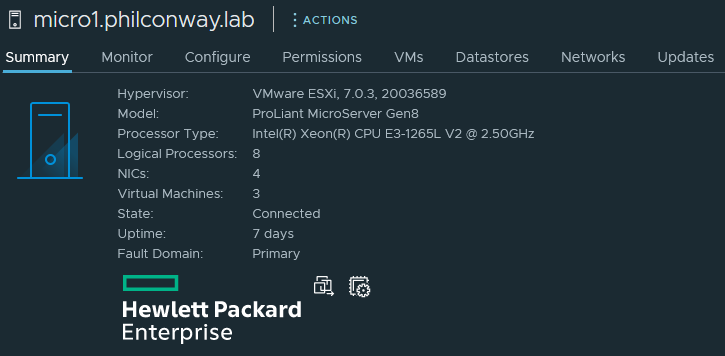
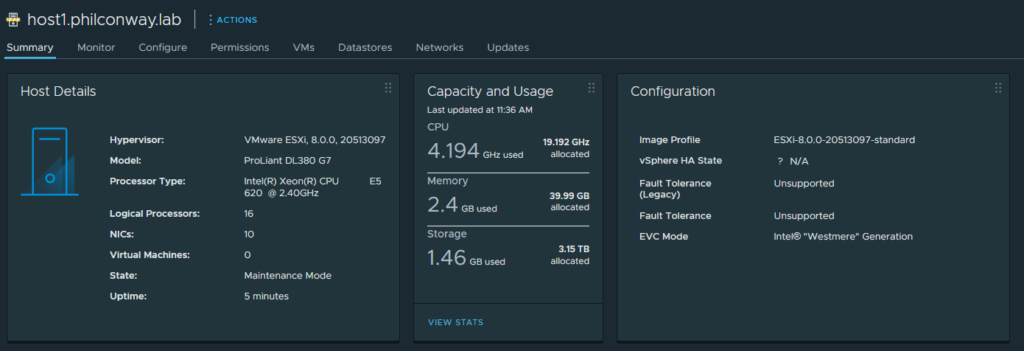
After upgrade and reboot, the box booted up successfully:
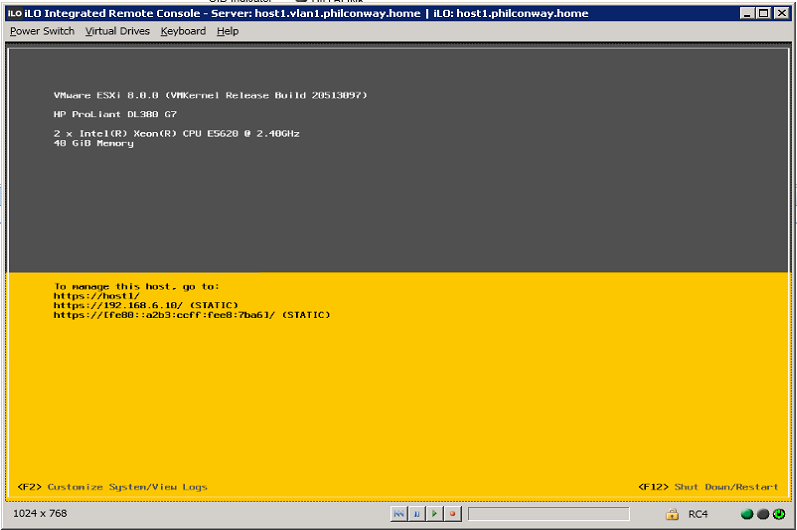
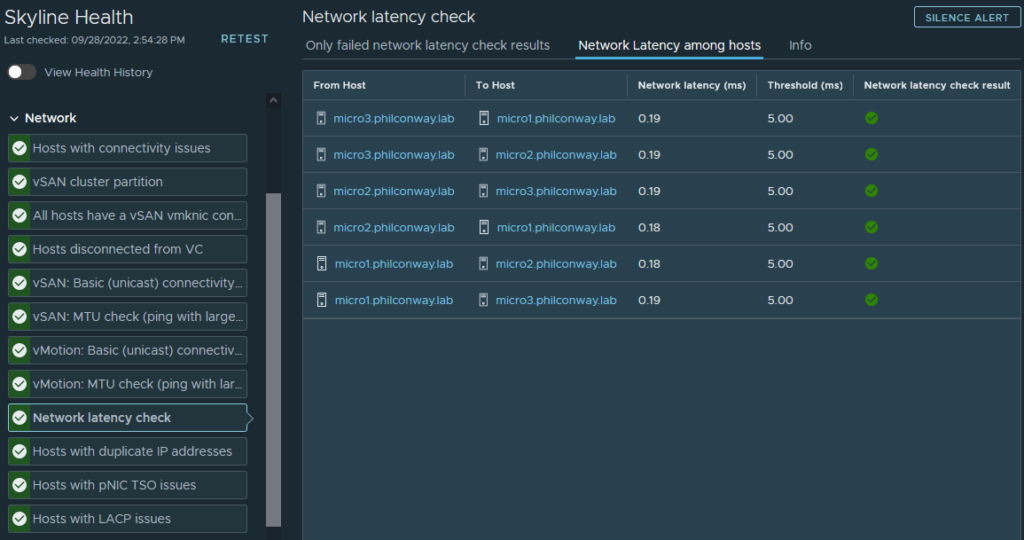
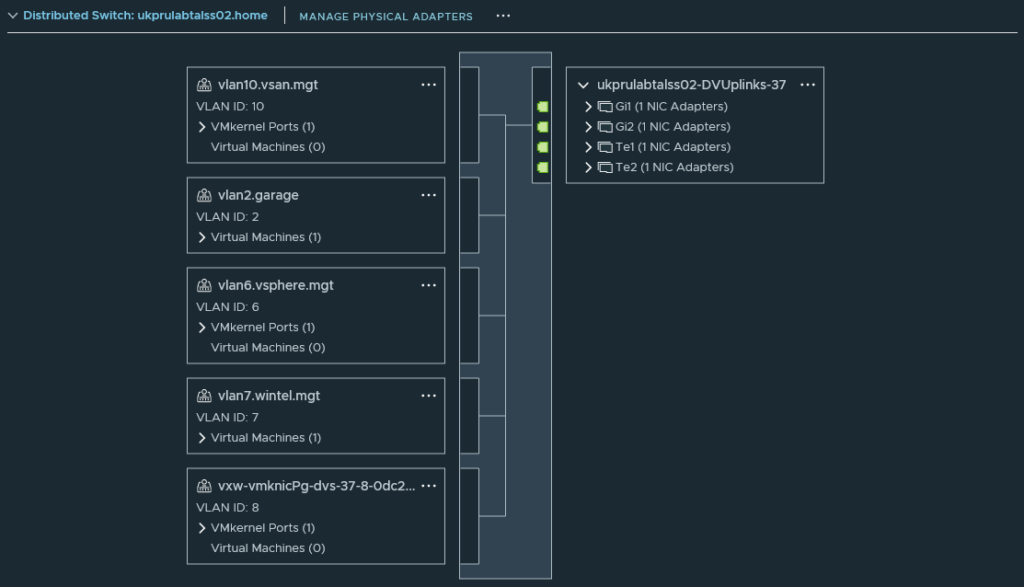
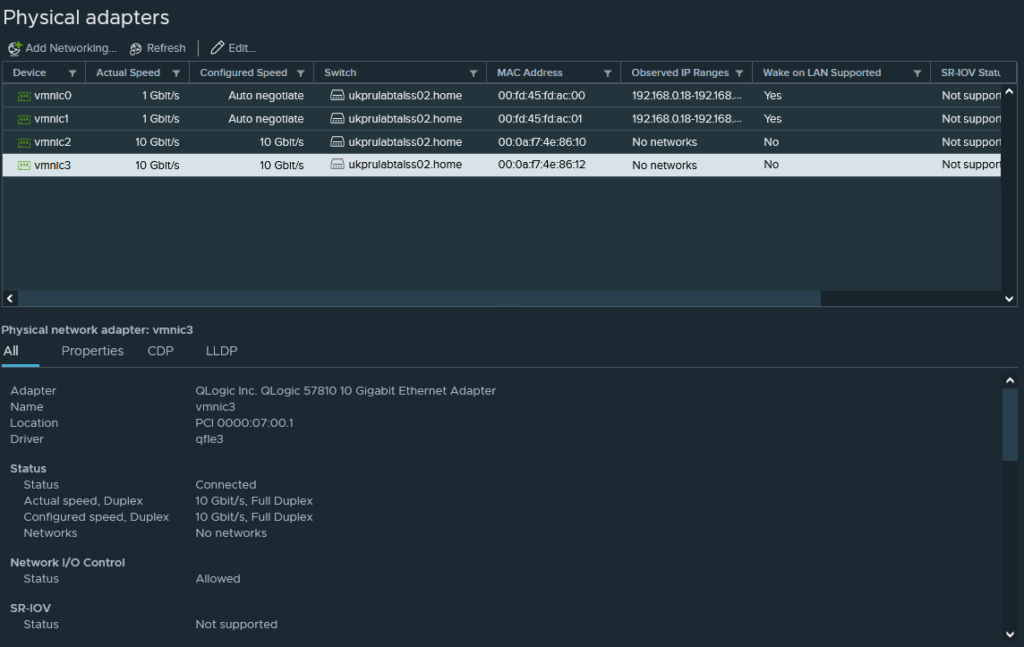
A quick check through vCenter shows all hardware detected and working successfully, including the multiple network add-in cards – Both the Intel 82571EB (4x1Gb) and QLogic 57810 (2x10Gb) showing up correctly.
Upgrading to vSphere 8 on HP ML350 G6
I thought that upgrading older hardware might prove more tricky. In my home lab I have a single ML350 G6, a server masquerading as a tower desktop PC. This box has 128Gb RAM and 15TB of storage, so it’s something I’d like to keep running on a recent version.
The ML350G6 originally had a pair of Nehalem E5520 CPUs. Nehalem shares the same CPU socket as Westmere, making a Westmere-based Xeon an easy drop-in upgrade (and adds AES-NI instruction sets as well as improvements for virtualisation), so I swapped this out for a pair of X5650s a few years back.
Upgrading this box to vSphere 7 resulted in the loss of the onboard NICs (luckily this particular server had additional NICs via an onboard card so everything continued to work after some quick repatching).
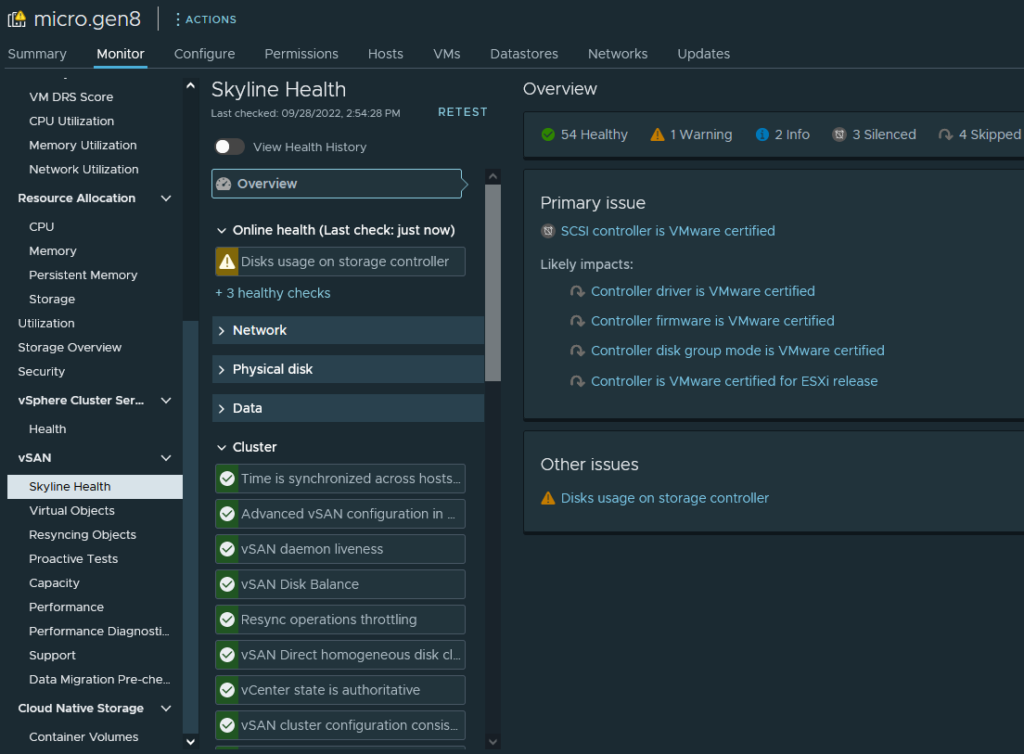
Running through the vSphere 8 installer resulted in the following error during pre-checks:
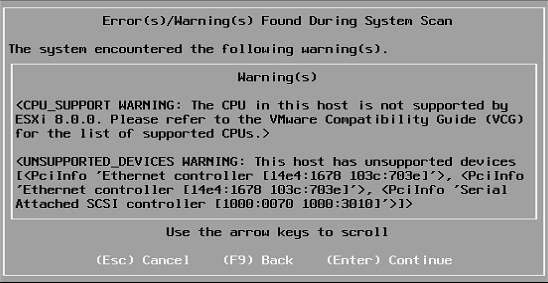
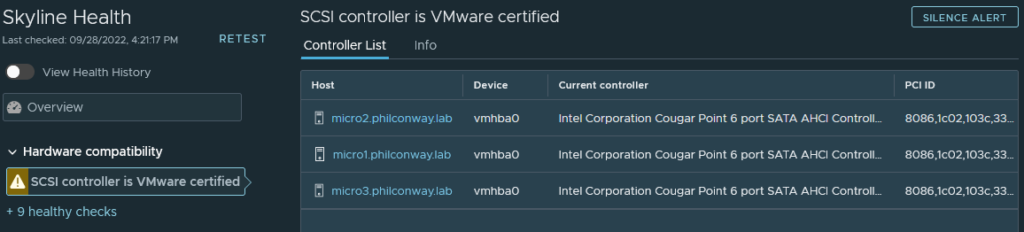
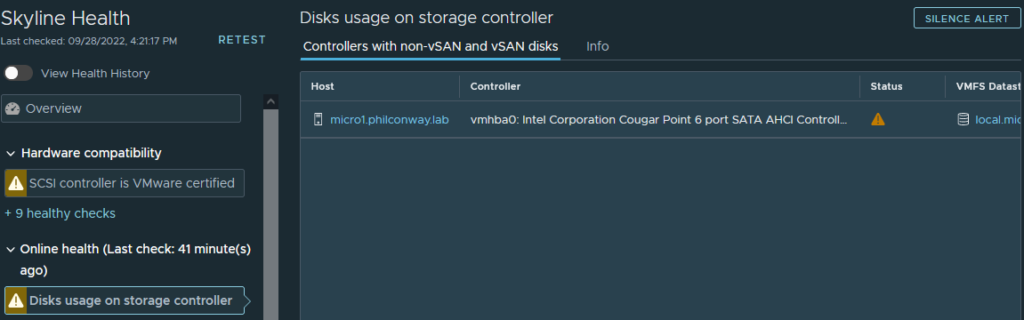
The CPU and NIC warnings were to be expected, I hoped the errors relating to the SAS controller are the add-in LSI board used for this server’s tape drive and not the built-in controller used for RAID/storage.
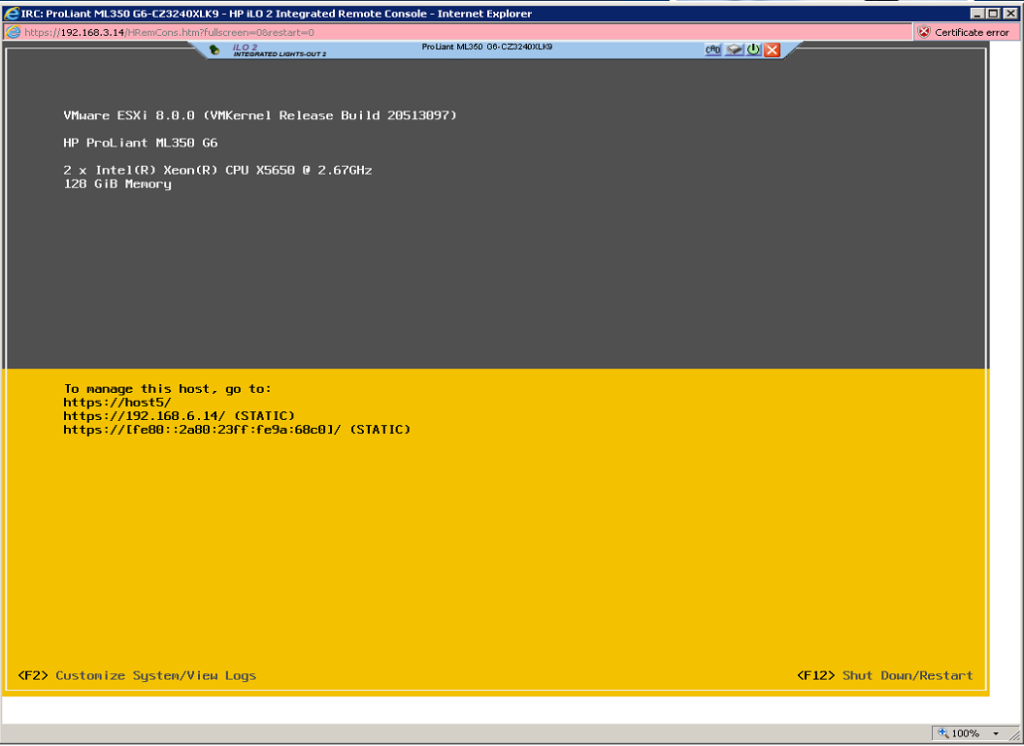
The server completed upgrade successfully and rebooted without issue.
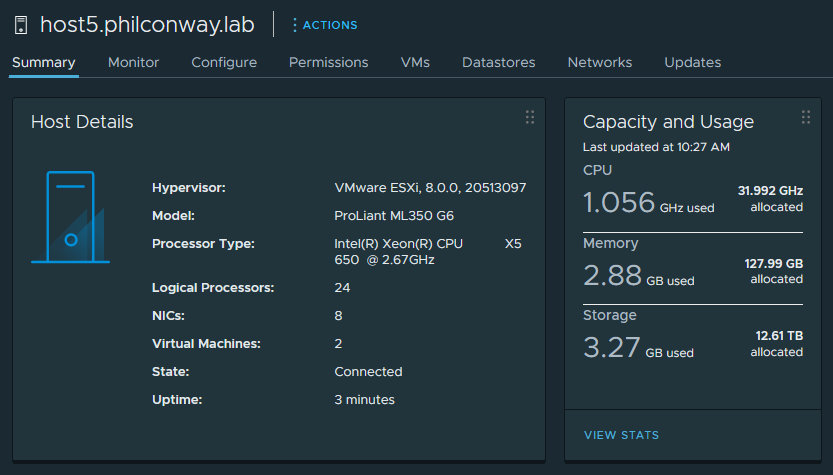
After running through some quick checks in vCenter, it appeared the box was running correctly with all hardware detected (apart from the onboard NICs and the add-on LSI SAS card).
Summary
For me, it was worth upgrading these boxes due to their decent storage and memory provision, as it prolongs the life of these servers and their usefulness in a lab capacity, but not without the loss of functionality in certain cases. I lost some onboard NICs, but due to having lots of additional NICs available (due to mucking around with uplink configurations for N-VDS/vDS & NSX), this is something I was able to work around very easily.
The experience when upgrading legacy hardware to vSphere 8 for lab use varies massively. Depending on the platform in question, whilst the CPU may support the hypervisor with some warning suppressed, it’s entirely possible (and highly likely) that the support of peripherals and additional hardware will determine the viability of any upgrade. Whilst common, popular hardware like HP 410i storage controllers and Intel X520 NICs seem to work without issue, don’t be surprised if more niche hardware or onboard components are no longer supported (and may require workaround or replacement in order to upgrade to vSphere 8). At this point it might be easier/cheaper to invest in new hosts 🙂